
Publications
Tanker market. Development prospects. Macroeconomic view
Tanker market. Development prospects. Macroeconomic view
SNAPSHOT OF THE CURRENT TANKER MARKET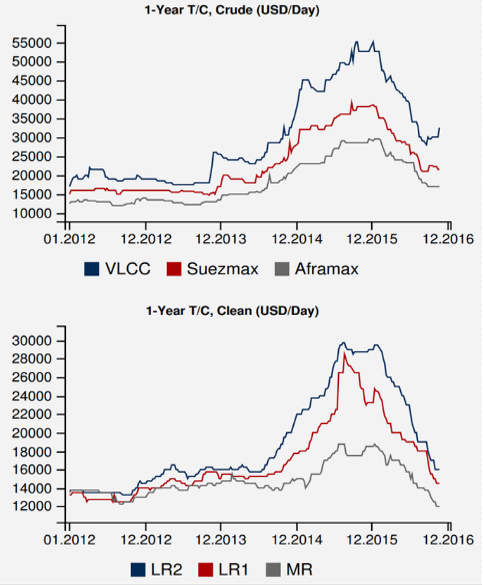
The large influx of new vessels due in 2017 is expected to tip the effective balance between supply and demand.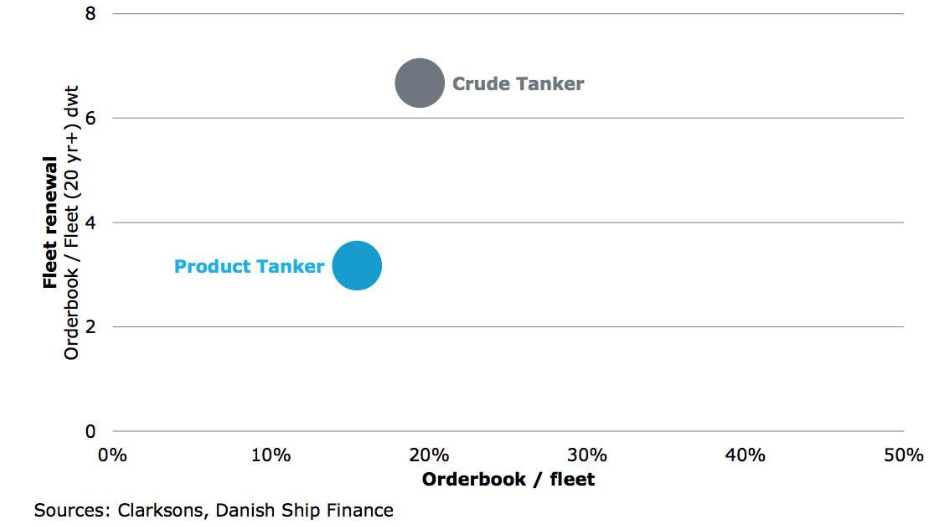
Underlying seaborne crude oil demand is only expected to grow modestly in the coming years.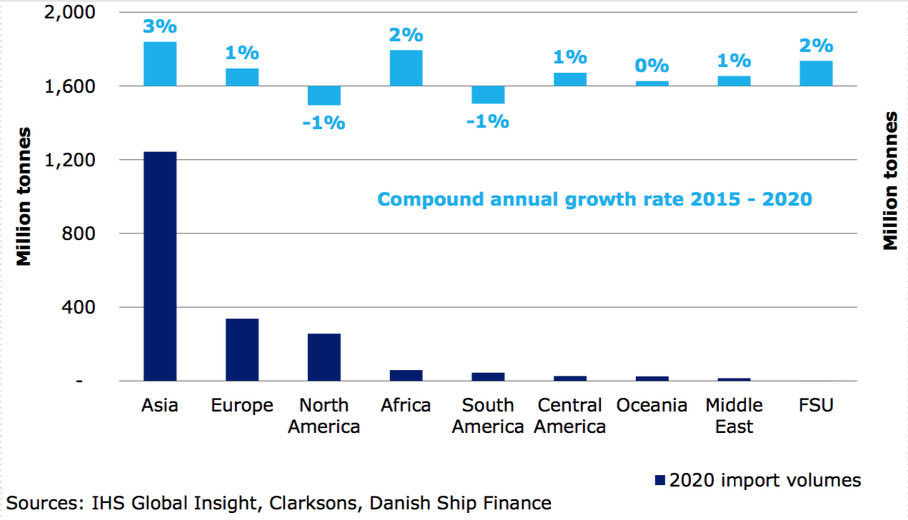
BIGGER PICTURE. MACROECONOMIC VIEW.
The outlook for global energy demand is driven by many factors, of which the three most important are:
- Population growth
- Urbanisation growth
- Economic growth
However the fourth industrial revolution will over time reduce their importance.
Professor Klaus Schwab: “We are at the beginning of a revolution that is fundamentally changing the way we live, work, and relate to one another.”

The fourth industrial revolution is disrupting some very basic mechanisms that have been facilitating massive growth in seaborne trade volumes over the past decades. These mechanisms may become outdated sooner than many people expect.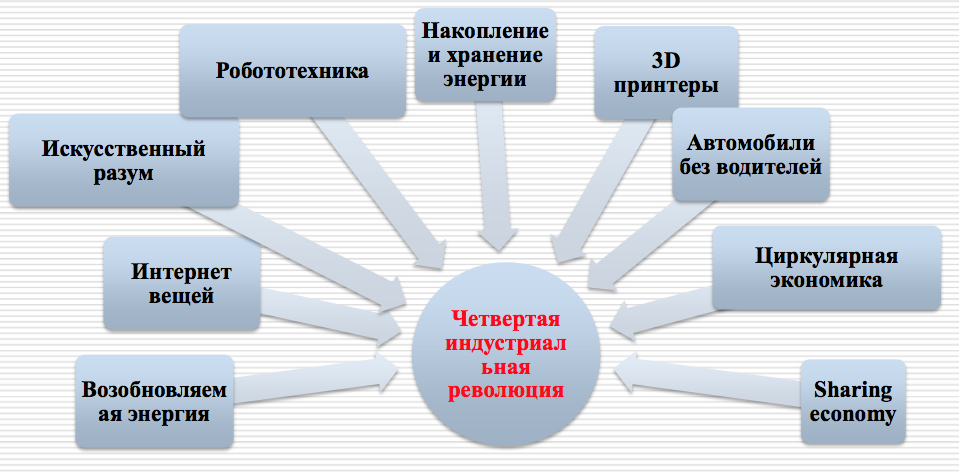
RENEWABLE ENERGY
In 2015 renewable energy accounted for the lion’s share of new electricity-generating capacity on a global scale.
In 2016, wind and solar photovoltaic systems (ranging from rooftop-integrated systems to large utility-scale power stations of hundreds of megawatts) are expected to be able to produce electricity at a cost in line with new coal and gas plants.
ELECTRIC VEHICLES
While electric vehicles represent less than 1% of the global stock of passenger cars, their share of new cars sold is expected to accelerate exponentially in the years to come, especially in large cities where distances tend to be shorter and access to electricity more widespread.
ROBOTICS
In a world where businesses stop chasing cheap labour, production will gravitate towards wherever the end-market is, because that will add value by shortening delivery times, reducing inventory costs and the like.
CIRCULAR ECONOMY
The goal for durable components - including metals and most plastics - is to reuse them or upgrade them for other productive applications through as many cycles as possible.
This approach contrasts sharply with today’s linear take-make- dispose economy, which wastes large amounts of embedded materials, energy and labour.
For the shipping industry one of the most disruptive innovations will be the design of materials that are built for recycling, reuse and remanufacturing.
CIRCULAR ECONOMY “RE-CYCLE, RE-USE, RE-NAULT!”
Any vehicle in the Renault lineup today is made from 30% recycled materials.
Renault Espace is 90% recyclable.
According to Renault, one remanufactured part uses 80% less energy, 88% less water, 92% fewer chemical products and generates 70% less waste during production compared with a new part.
DISRUPTIVE EFFECTS
Urbanisation process is continuing, but it is diverging from past trends and is tending to follow new routes that give individual consumers access to more goods using fewer resources (including energy) and requiring less seaborne transportation.
DISRUPTIVE EFFECTS
Wealthy consumers in developed economies and China are about to retire and are being replaced by plentiful but relatively poor emerging consumers elsewhere.
This transformation is expected to have a major impact on trade flows and trade dynamics.
DISRUPTIVE EFFECTS
As consumers in North America, Europe, Japan and China age, the combined workforces of these economies are set to shrink by approximately 100 million people (i.e. 6%) within the next 15 years.
Consequently, from a demographic perspective these economies are expected to witness a decline in seaborne import volumes of about 12% in the period from 2015 to 2030.
DISRUPTIVE EFFECTS
Global value chains are expected to shorten: from raw materials to intermediate goods to finished goods. Seaborne trade volumes may stagnate or begin to decline, travel distances may shorten.
CONCLUSION
Current turmoil is more fundamental than simply a reflection of the growing overcapacity created in the wake of the global financial crisis.
This is neither about cyclicality nor volatility but about a transformation in demand that over time has the potential to redefine the forces at play.
Evgeniy Dolgikh, 05.12.2016
download pdf back